



Today, Openai rival Anthropic announced the Cloud 4 model, which is much better than Cloud 3 in the benchmark, but we are disappointed with the same 200,000 reference window limits.
In a blog post, Anthropic stated that Cloud Oppus is the most powerful model of the company, and it is also the best model for coding in the industry.
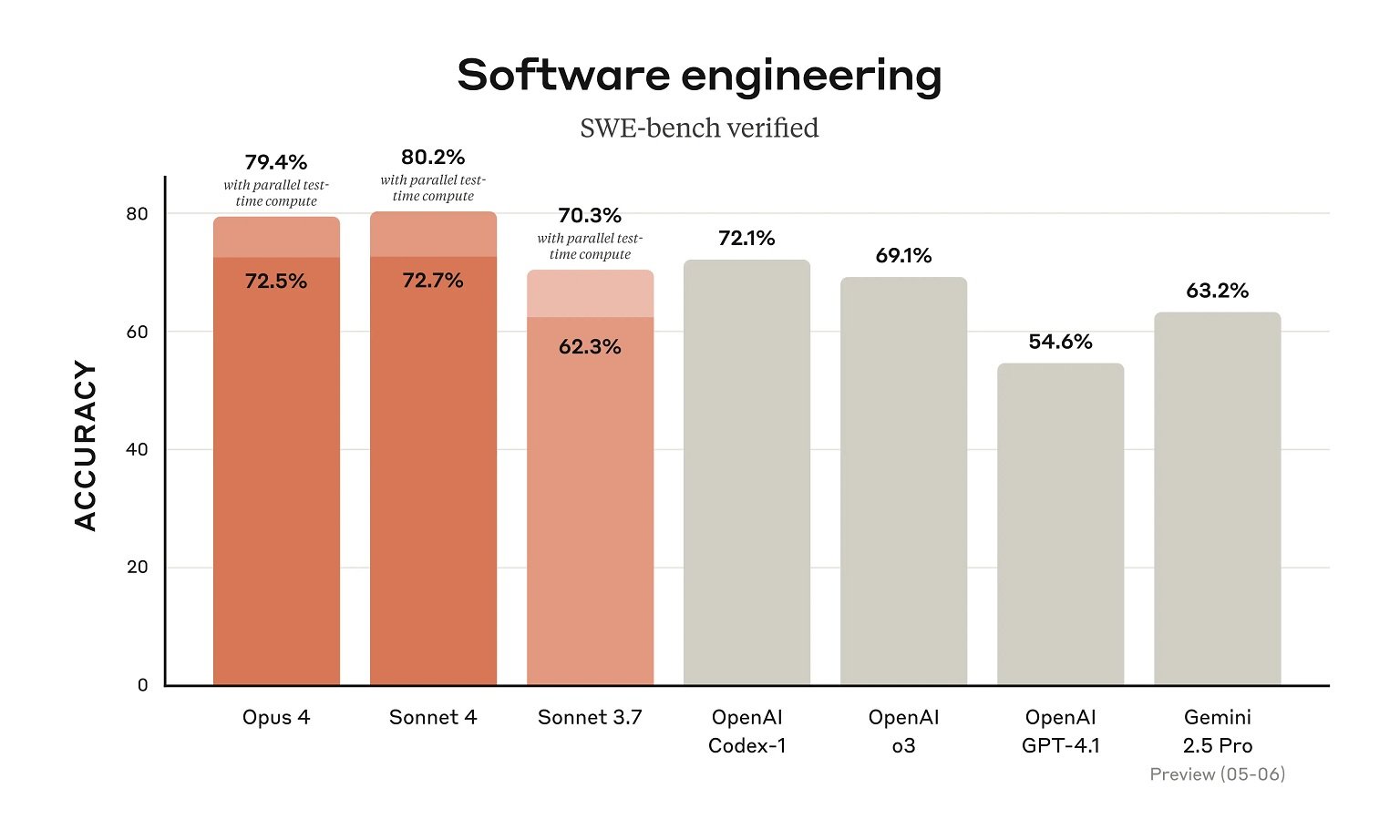
For example, SWE-Bench (SWE Software is small for engineering benchmark), Cloud Ops 4 scored 72.5 percent and 43.2 on the terminal-bench.
“It provides continuous performance on long -running tasks, which requires focused efforts and thousands of stages, with the ability to work continuously for several hours, dramatically improved all sonnet models better better and can complete AI agents,” anthropic noted,
While the benchmark placed Cloud 4 Sonnet and Oppus in its predecessors and competitors such as Gemini 2.5 Pro coding, we are still concerned about the 200,000 reference window range of the model.
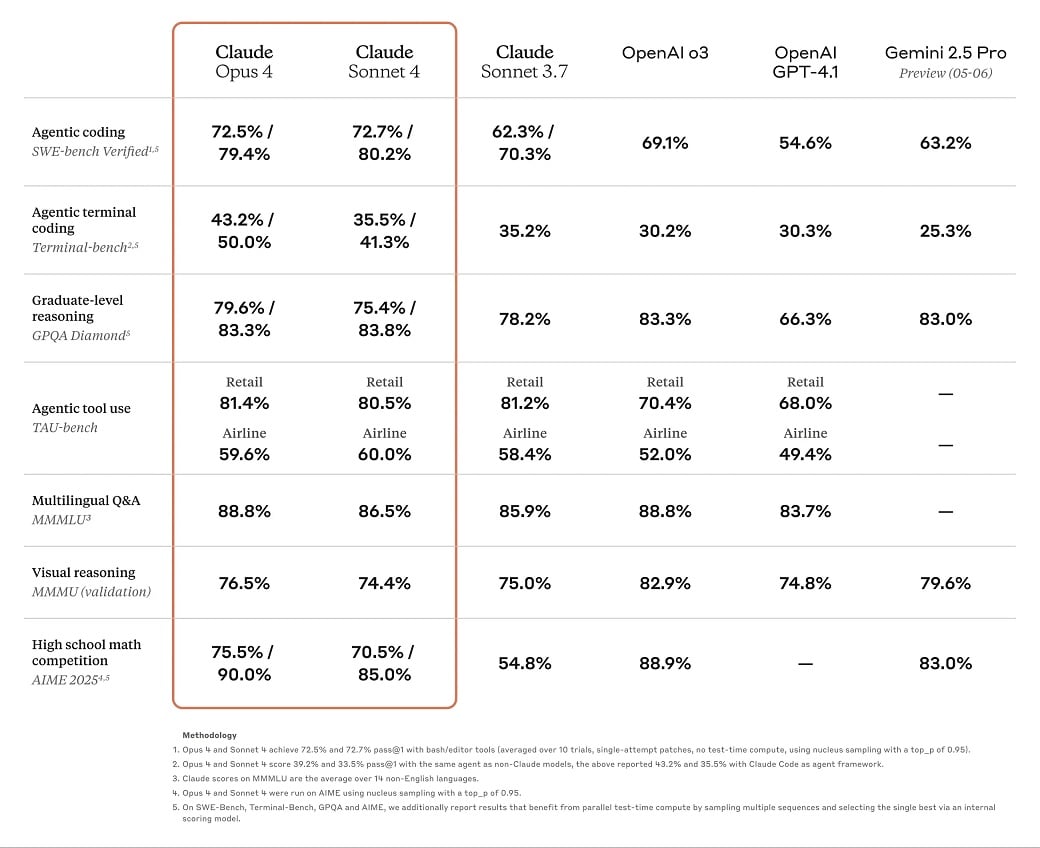
This may be one of the reasons why Cloud 4 models in these benchmarks coding and complex-solving functions are excels, as these models are not being tested against a large reference.
For comparison, the Gemini 2.5 Pro ship of Google with 1 million token reference window and support for 2 million reference windows is also in work.
4.1 models of Chatgpt also provide up to a million reference window.
| Sample | Description | Input | Prompt Caching Wright | Prompt Caching Reed | Production | Reference window | Batch resource discount |
|---|---|---|---|---|---|---|---|
| Cloud Opus 4 | The most intelligent model for complex tasks | $ 15 / mtok | $ 18.75 / Mtok | $ 1.50 / mtok | $ 75 / Mtok | 200k | 50% discount with batch processing |
| Cloud sonnet 4 | Optimal balance of intelligence, cost and speed | $ 3 / mtok | $ 3.75 / mtok | $ 0.30 / Mtok | $ 15 / mtok | 200k | 50% discount with batch processing |
Cloud is still behind the competition when it comes to the reference window, which is important in large projects.

Based on the analysis of 14M malicious tasks, search for the top 10 MITERAT & CK techniques behind the 93% attacks and how to defend them against them.