



Google says an API management issue is behind the Google Cloud Outage on Thursday, which disrupted or brought down its services and many other online platforms.
Google says that the cloud outage began around 10:49 ET and ended at 3:49 ET, causing issues for millions of users worldwide for more than three hours.
Apart from Google Cloud, this phenomenon also influenced Gmail, Google Calendar, Google Chat, Google Cloud Search, Google Docs, Google Docs, Google Drive, Google Meet, Google Tacks, Google Voice, Google Lens, Discover and Voice Society.
However, it also caused extensive issues for third-party platforms, which rely on Google Cloud, but not limited to a limited number of cloudflair services dependent on Spotify, Discord, Snapchat, NPM, Firebase Studio, and Workers KV Kev key-value stores.
“We are deeply sorry for the influence of all our users and their customers that this service disintegrated/outage. Businesses will be big and small trusts Google Cloud and we will better,” Google said,
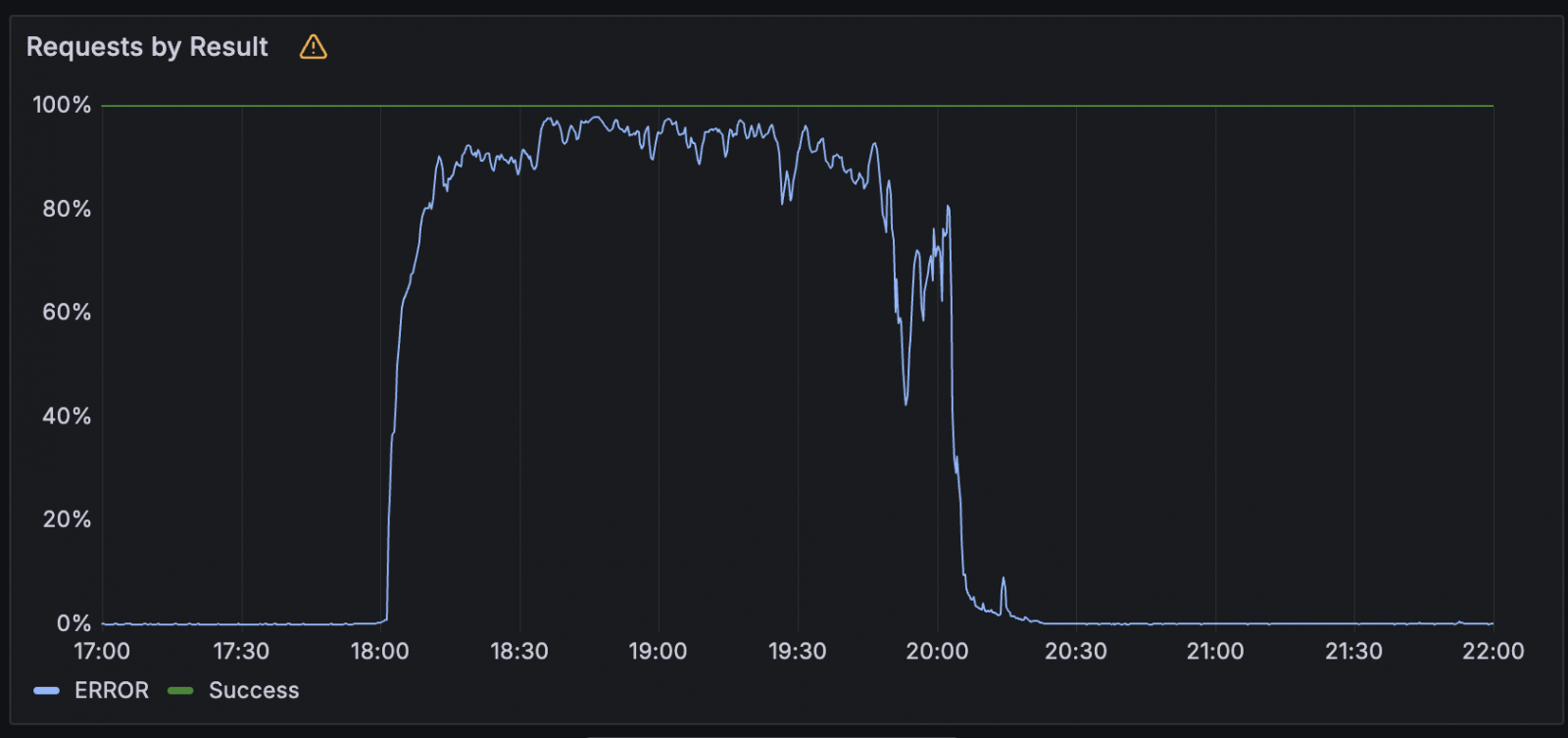
Although it is still working on publishing a full event report, Google today reported that there was an increase in the number of 503 errors in external API requests during yesterday’s three -hour long outage.
As the company explained today, its Google Cloud API management platform failed due to invalid data, an issue that was discovered and removed immediately as it lacked effective testing and error-handling system.
“From our initial analysis, the issue was due to an invalid automatic quota update to our API management system, which was distributed globally, rejecting the external API requests. We bypass the aggressive quota check to fix us, which allowed recovery in most areas within 2 hours.”
“However, the quota policy database overloaded in the US-Central 1, resulting in a very long recovery in the area. Many products had a moderate residual effect (eg backlog) by an hour after reducing the primary issue and after that a small number was cured.”
Cloudflaare service taken by Google’s outage
After successfully restoring his own affected services, Claudflair also revealed in a post -mortem that yesterday’s incident did not occur due to the security incident and no data was lost.
“The reason for this outage was due to failure in the underlying storage infrastructure used by our workers KV service, which is a significant dependence for many cloudflair products and confidence for configuration, authentication and asset distribution in affected services,” Cloudflare said.
“A part of this infrastructure is supported by a third-party cloud provider, who today experienced an outage and directly influenced the availability of our KV service.”
Even though it did not share the name of the cloud provider behind Thursday’s outage, a Claudflare spokesperson told BlappingCopper yesterday that only Claudflare services relying on Google Cloud were affected.
In response to this incident, Cloudflare says it will transfer the KV’s central store to its own R2 object storage to reduce external dependence and prevent similar issues in the future.

Patching meant complex scripts, long and endless fire drills. No more.
In this new guide, the tines break down how it is leveling with modern organ automation. Patch fast, reduce overhead, and focus on strategic tasks – no complex script is required.