



Cloudflare confirmed that yesterday mass service outage was not due to safety incident and no data is lost.
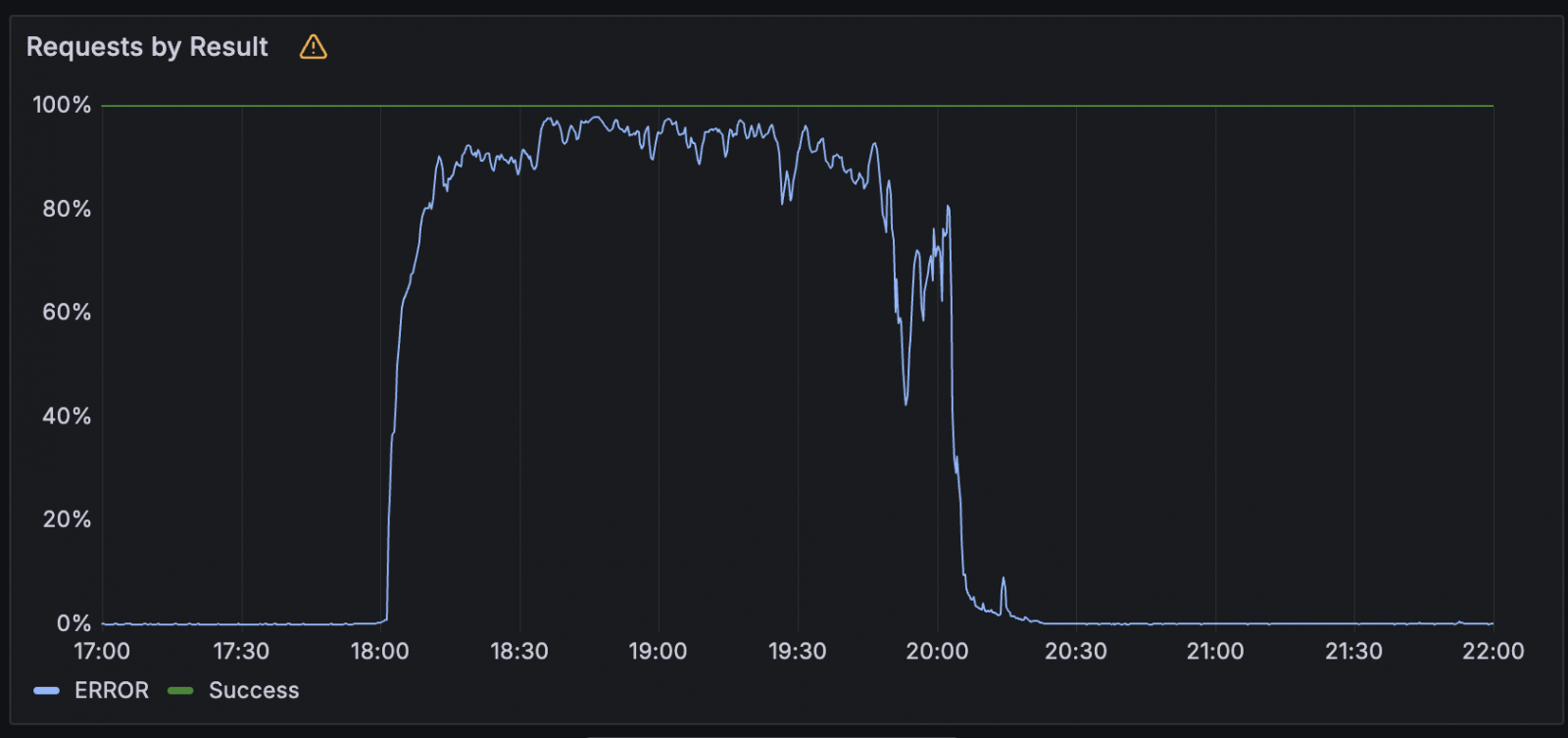
This issue has been reduced to a great extent. It started yesterday 17:52 UTC when the Workers KV (Ke-Value) system became completely offline, causing extensive service losses in many age computing and AI services.
Worker KV is a globally distributed, consistent key-value store used by Cloudflare workers, the company’s server-free computing platform. It is a fundamental piece in many cloudflave services and a failure can cause cascading issues in many components.
Disruption also affected other services used by millions, especially Google Cloud Platform.
Source: Cloudflare
In a post-mortem, Cloudflair states that the outage lasted for about 2.5 hours and the root cause a third-party cloud provider outage was failure in the underlying storage infrastructure of the workers due to the outage.
“The reason for this outage was due to a failure in the underlying storage infrastructure used by our workers KV service, which is a significant dependence for many cloudflair products and confidence for configuration, authentication and asset distribution in affected services,” Cloudflare They say,
“A part of this infrastructure is supported by a third-party cloud provider, who today experienced an outage and directly influenced the availability of our KV service.”
Cloudflare has determined the effect of the event on each service:
- Worker K.V. – Backnd storage experienced 90.22% failure rate due to non -availability, which affects all uncaded reeds and rights.
- Entry, taunt, entrance -All of them faced significant failures in identification-based certification, session handling and policy enforcement, which due to the dependence of workers on KV, unable to register new equipment, and with gateway proxy and disintegration of DOH questions.
- Dashboard, Turnstell, Challenges – Experienced comprehensive login and captcha verification failures, tokens reusable due to killing switch activation on turns.
- Browser isolation and browser rendering -Failed to start or maintain link-based sessions and browser rendering tasks due to cascading failures in access and gateway.
- Section, picture, page – Experienced major functional breakdowns: stream playback and live streaming failure, image uploaded 0% for success, and makes the page/serves at the peak at ~ 100% failure.
- Workers A and Autorag – Models were completely unavailable due to configuration, routing and dependence on KV for sequencing tasks.
- Durable items, D1, queues – Services made on the same storage layer as KV faced complete non -availability for 22% error rate or message queue and data operation.
- Realtime and AI Gateway -Reltime turn/SFU and AI Gateway faced near-cool service disintegration due to inability to recreate the configuration from workers KV.
- Tongue and labor assets -Complete or partial failure was observed in loading or updating the cornfigurations and stable assets, although the end-user impact was limited to the scope.
- CDN, workers for platforms, labor construction – In some places, delay and regional errors increased, 100% fails during the incident with new workers.
In response to this outage, Cloudflare says it will intensify many flexibility-centered changes, mainly the workers will eliminate the dependence on the single third-party cloud provider for KV backndary storage.
Gradually, the central store of the KV will be migrated to its R2 object storage of cloudflare to reduce external dependence.
Cloudflare is also planning to develop new tools to implement cross-servis safety measures and to restore services during storage outages, which can prevent traffic growth that can recover the system and cause secondary failures.

Patching meant complex scripts, long and endless fire drills. No more.
In this new guide, the tines break down how it is leveling with modern organ automation. Patch fast, reduce overhead, and focus on strategic tasks – no complex script is required.